pipeline是什么?
它是一个工作流平台,能够编译部署机器学习的工作流,可以定义复杂的数据dag流程,并提供可视化的流程展示和结果展示。 pipeline是kubeflow里面非常重要的一个组件,用来将整个机器学习任务给串联起来。
pipelines平台组成
- 一个用来跟踪和管理job以及运行的web ui界面
- 一个用来调度多个ml工作流程步骤的引擎
- 用来定义和操作pipeline以及components的sdk
- 用sdk来与系统交互的notebook
pipeline的目标
- 端到端的编排方式:开启并简化机器学习pipelines的编排方式
- 简单的实现:可以很容易的尝试各种想法和技术并管理各种训练模型
- 简单的重用:允许重复使用components和pipeline去快速创建端到端的解决方式且不用每次重新构建。
pipelien的核心概念
pipelines实现了一个工作流模型。所谓工作流,或者称之为流水线(pipeline),可以将其当做一个有向无环图(DAG)。其中的每一个节点,在pipelines 的语义下被称作组件(component)。组件在图中作为一个节点,其会处理真正的逻辑,比如预处理,数据清洗,模型训练等等。每一个组件负责的功能不同,但有一个共同点,即组件都是以 Docker 镜像的方式被打包,以容器的方式被运行的。这也是与 kubeflow 社区的 Run ML on Kubernetes 这一愿景相统一的。
实验(experiment)是一个工作空间,在其中可以针对流水线尝试不同的配置。运行(run)是流水线的一次执行,用户在执行的过程中可以看到每一步的输出文件,以及日志。步(step)是组件的一次运行,步与组件的关系就像是运行与流水线的关系一样。步输出工件(step output artifacts)是在组件的一次运行结束后输出的,能被系统的前端理解并渲染可视化的文件。
概念列表
- Pipeline: pipeline用来定义一组操作的流水线,每一步都是一个component。可以简单把它理解成用来描述操作的静态模版。
- Experiment: 工作空间,管理一组运行的任务。
- Graph: 用来描述pipeline步骤的有向无环图。
- Run: 真实运行pipeline的任务,这个任务会启动多个pod来进行计算。
- Step: Component对应实体,一个step会对应一个pod。
- Recurring run: 定时任务,可以用
run trigger进行触发。 - Component: 一个容器操作,可以通过pipeline的sdk 定义。每一个component 可以定义定义输出(output)和产物(artifact), 输出可以通过设置下一步的环境变量,作为下一步的输入, artifact 是组件运行完成后写入一个约定格式文件,在界面上可以被渲染展示。
其关联关系如下图:
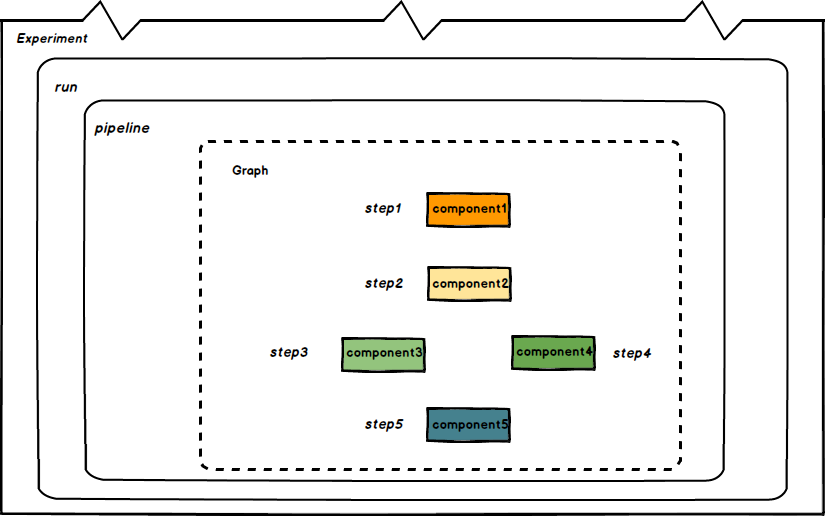
pipeline架构
pipeline通用步骤
- 编写python文件来定义pipeline
- 使用python sdk、cli来编译其pipeline并生成压缩包
- 使用python sdk、cli来上传到pipeline service
- 使用pipeline压缩包来创建一个任务(run),并为其定义输出输出参数
- 输出其任务状态以及执行结果
其步骤图如下:
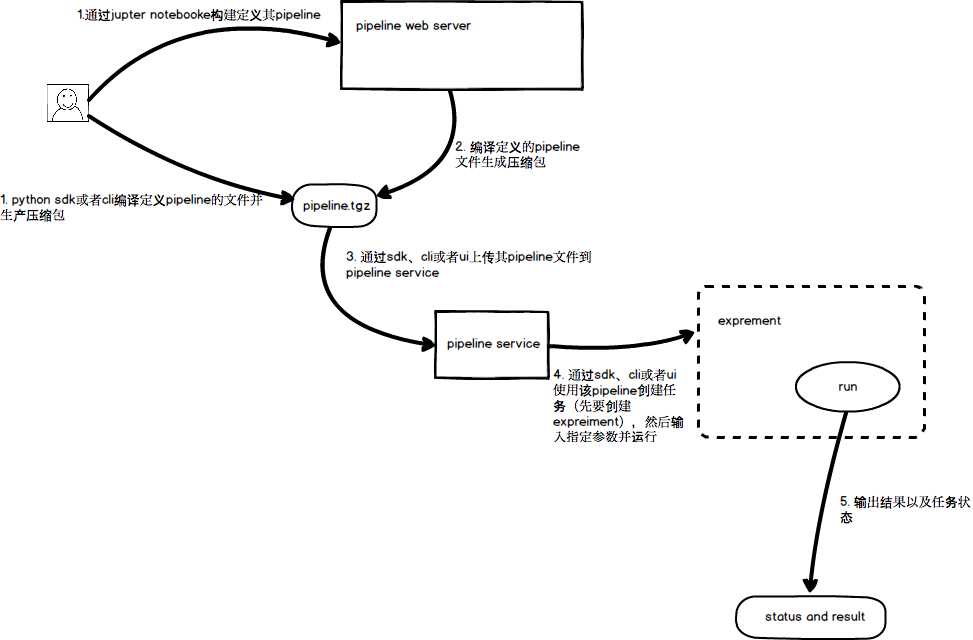
pipeline执行过程中涉及到的概念
- Python SDK
通过kubeflow pipelines的DSL创建一个组件或者明确一个pipeline。
- DSL compiler
DSL compiler会转换定义pipeline的python code到一个静态配置(YAML)
- Pipeline Service
调用管道服务来创建从静态配置运行的管道。
- kubenertes resource
pipeline service调用k8s api服务器去创建用来运行pipeline所必须的k8s资源(kubernetes resources-CRDs)
- Orchestration controllers
一组用来编排运行pipeline所需要执行的容器的控制器。这些容器运行在k8s的pod中。
- Artiface storage
pods存储两种类型的数据:
1.Metadata(元数据): 实验、任务、运行的管道还有单梯度的指标。pipeline将这些元数据存放在mysql数据库中。
2.Artifacts(归档文件):pipeline的包、视图以及大规模指标。大规模指标可以用来debug运行中的pipeline或者调查单个运行的pipelien的性能。pipeline存放这些归档文件到minio server或者云存储上。
- Persistence agent and ML metadata
管道持久化代理监控了pipeline service创建的k8s资源并持久化了在ml metadata service服务中资源的状态。管道持久化代理还记录了执行容器的输入以及输出。这些输入输出是由容器的参数以及数据归档后的url组成。
- Pipeline web server
web server会从各种各样的服务收集数据并展现出相关的视图,比如正在运行的pipelines列表,pipeline的执行历史,数据的归档文件列表,每个pipeline运行时的debbugging信息以及执行状态。
其整个pipeline架构以及执行流程如下:
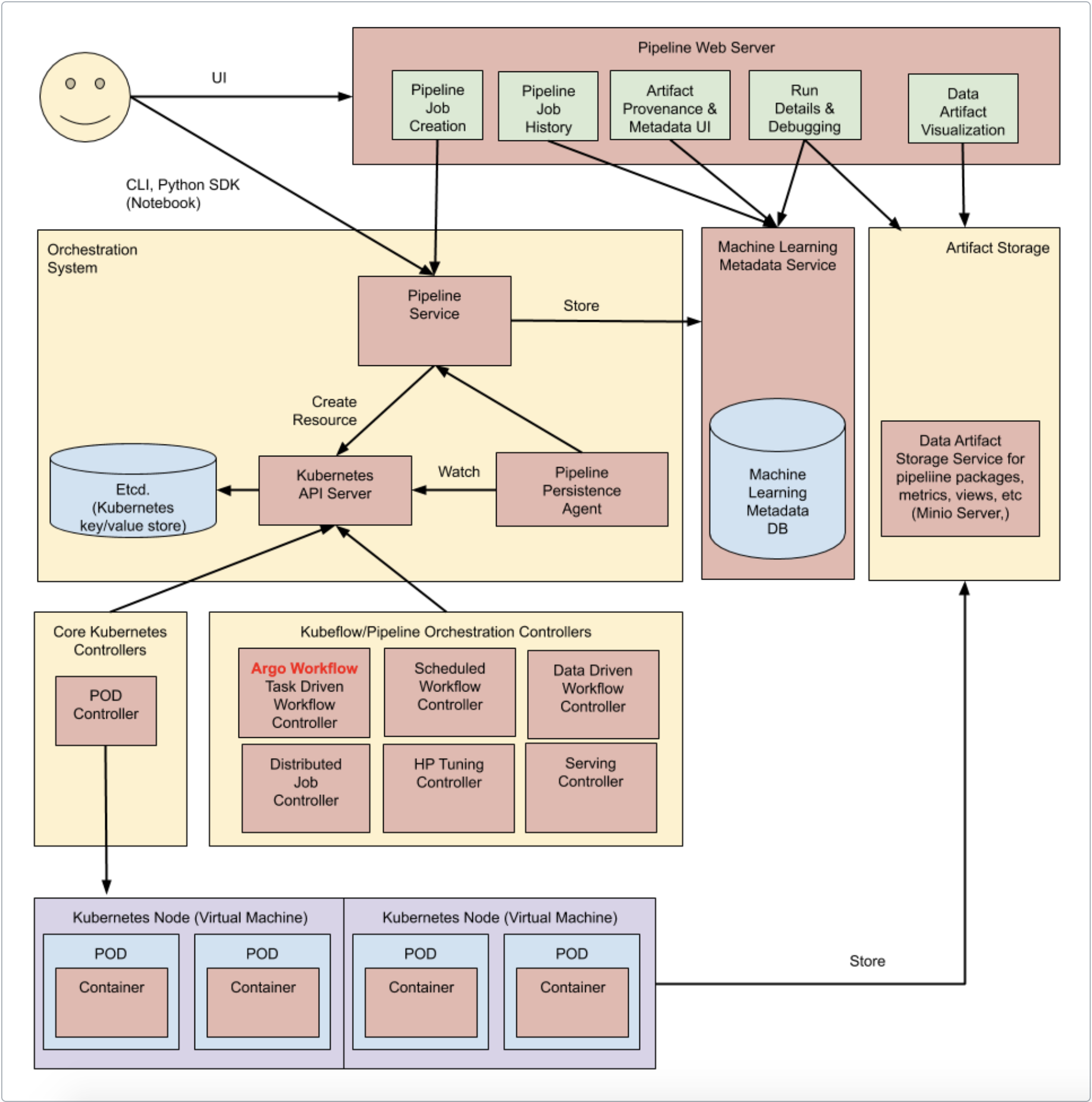
pipeline提供的交互工具
python sdk
kubeflow pipeline官方提供的python sdk包含以下几个模块:
-kfp.compiler
该模块中包含了用来编译描述pipeline的python代码到一个pipeline service可以处理的静态文件中的方法和类。Pipeline Service会将这个静态文件转换成一组k8s资源。
-kfp.components
该模块包含了与pipeline组件进行交互的方法和类。比如组件的构建以及导入导出。
-kfp.dsl
用来定义ContainerOp以及VolumeOp等真正和K8s交互的模块。是一个比较重要的模块。
-kfp.Client
负责与pipeline service进行交互,比如提交、上传、运行pipeline等等。
-extension
主要是云上的一些扩展模块用来支持kubeflow pipeline。比如gcp、aws等等。
-diagnose_me modules
环境诊断工具。
kubeflow pipeline cli tools
代替sdk中的一些api,可以直接使用cli来进行操作。
比如kfp diagnose_me、kfp pipeline <COMMAND>、kfp run <COMMAND>、kfp --endpoint <ENDPOINT>